We at Miðeind are excited to introduce a new leaderboard that evaluates the performance of large language models on Icelandic benchmarks. The leaderboard is an important tool for monitoring the development of artificial intelligence technology in Icelandic and can help in selecting appropriate models for various tasks. We will discuss the importance of Icelandic benchmarks, explain some challenges that arise when testing large language models, and introduce the six Icelandic benchmarks that we use to test the models. The leaderboard can be accessed on the Hugging Face website: https://huggingface.co/spaces/mideind/icelandic-llm-leaderboard
Language models are used in countless different ways. Some serve as chatbots in banking services, others are assigned the role of personal assistants, and still others are used to proofread and translate novels. The prerequisite for all these use cases is that the model understands the requested language and can adequately express itself in it.
So far, there has been a strong emphasis on creating benchmarks in English, as proficiency in other languages was initially very lacking. As a result, smaller languages like Icelandic have been left behind, and we often desperately need benchmarks that evaluate the ability of models on tasks that are generally considered solved for larger languages.
Just as an American lawyer would likely struggle to provide legal advice in Icelandic, it may be unwise to assume that proficiency of language models in English transfers to Icelandic.
In order to be able to choose the right model for the job, there is a strong need for diverse benchmarks that measure Icelandic proficiency, but also to assess what skills the current generation of models lacks so that improvements can be made.
When creating automated benchmarks for language models, we face a similar problem to what many teachers are likely familiar with. Multiple-choice questions are easy to grade and score but are harder to compose, and they provide a narrow picture of the test-taker's knowledge. On the other hand, it's often easier to compose questions with written answers, and they elicit a different kind of knowledge. However, it can be considerably more difficult to review and grade such answers, especially in an automated manner.
Some abilities of language models are also nearly impossible to test with multiple-choice questions, such as language generation quality. By definition, to evaluate the quality of generated language, the model needs to generate it.
In recent years, the models have advanced rapidly, and so too has the need for sufficiently difficult benchmarks. To illustrate this, we can look at MMLU [1], a benchmark that evaluates models' knowledge at high school and undergraduate levels across various disciplines. When it was released in 2020, the benchmark proved particularly difficult for language models of that time, with none achieving more than 50% of the points. Today's language models, however, ace it, with many scoring nearly 90% [2]. The GPQA benchmark [3] was later released in 2023 and measures even more specialised knowledge up to master's and doctoral levels. It still proves challenging, with the best models of today scoring below 80% [2].
Generally, a benchmark is considered "solved" when a model scores higher than 90-95%. Benchmarks often contain some flawed examples, and improvements beyond such a high score become less and less significant. At this point, the benchmark ceases to be a good touchstone for progress, and a new, more difficult benchmark is needed.
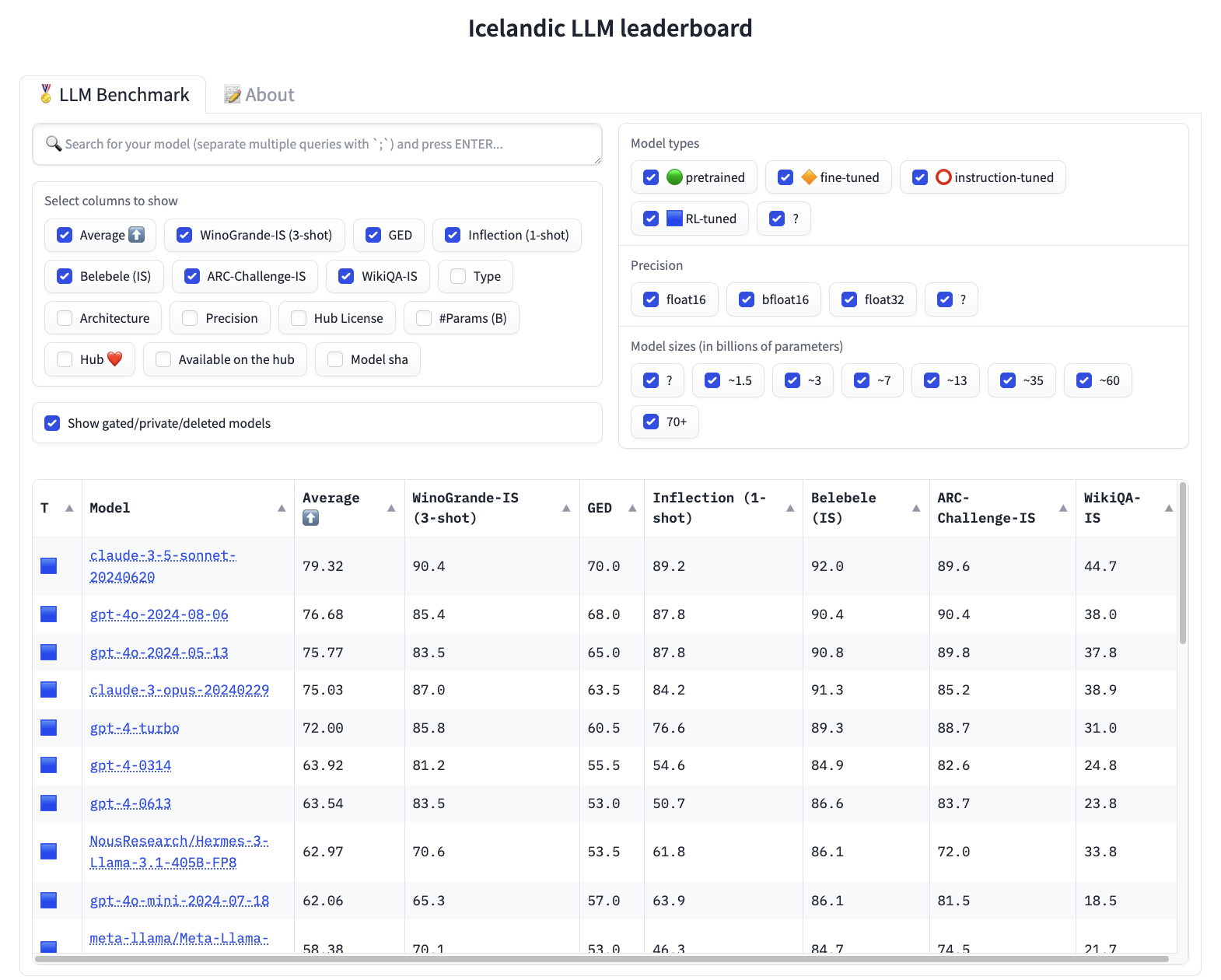
The Icelandic leaderboard consists of six benchmarks. They were selected to provide the most comprehensive picture of language models' proficiency in Icelandic and assess different aspects such as language comprehension, cultural knowledge, and grammar. The benchmarks are a mix of translated English benchmarks and specially developed Icelandic benchmarks.
Winogrande is designed to assess commonsense reasoning and ability to resolve ambiguity in language from context, something that should be very natural for humans. We manually translated and localised 1000 examples from the original benchmark by Allen Institute for AI [4]. Each example is set up as a sentence containing a blank and two options for the blank, both of which are grammatically correct, but only one fits the context of the sentence. This requires the model to understand context and have general inference ability. Example:
"The child couldn't fit the book in the bag because _ was too big". Which would be more correct to put in the blank, "the book" or "the bag"?
Correct answer: "the book"
Original:
„Barnið kom bókinni ekki fyrir í töskunni því _ var of stór“. Hvort væri réttara að setja í eyðuna „bókin“ eða „taskan“?
Rétt svar: „bókin“
The Case Declension Benchmark evaluates the ability to decline noun phrases in all cases, singular and plural. It is set up so that the model is given a noun phrase containing an adjective and a noun and is asked to respond with its declined form in a specific number and case. Example:
What is the declined form of the noun phrase "rakleidd járnhönd" in the accusative plural without the article?
Correct answer: "rakleiddar járnhendur"
Original:
Hver er beygingarmynd nafnliðarins „rakleidd járnhönd“ í þolfalli fleirtölu án greinis?
Rétt svar: „rakleiddar járnhendur“
WikipediaQA is a benchmark designed to assess a model's knowledge of Icelandic culture, traditions, and history. Questions and answers were automatically extracted from the Icelandic part of Wikipedia with the help of GPT-4o and then manually reviewed by a human. The questions are presented to the model being tested, which answers with one or more sentences. The answers are then compared to a standard answer by having GPT-4o assess whether the given answer is substantively correct. Example:
What was Kolviðarhóll, which played a role in Icelandic travel culture in the 19th and 20th centuries?
Correct answer: A resting place for travelers
Original:
Hvað var Kolviðarhóll, sem gegndi hlutverki í íslenskri ferðamenningu á 19. og 20. öld?
Rétt svar: Áningarstaður ferðamanna
Grammatical Error Detection (GED) measures a model's ability to analyze grammatical errors. We do this by giving the model 100 corrected and 100 uncorrected sentences from the Icelandic Error Corpus and asking it to mark whether each individual sentence contains errors or not. Example:
Sentence: "Þetta bendir til þess að kvikan sé þarna á einhverrri lágréttri hreyfingu og þetta svipar mjög til þess sem gerðist fyrir gosið."
Correct answer: Contains errors. There are three errors here: The word "einhverri" is incorrectly written with three r's, "lágréttri" should be "láréttri", and "þetta svipar" should be "þessu svipar".
Belebele is a reading comprehension benchmark created by Facebook [5], where the task is to read a text and answer multiple-choice questions about its content. Example:
First, read this text: "Lodin also said officials decided to cancel the runoff in order to save Afghans the expense and security risk of another election. Diplomats said that they had found enough ambiguity in the Afghan constitution to determine the runoff as unnecessary. This contradicts earlier reports, which said that cancelling the runoff would have been against the constitution."
According to the passage, which reason was not used to explain the canceled runoff?
A: Security risk
B: A contradiction of the constitution
C: High expenses
D: Constitutional ambiguity
Correct answer: B
Original:
Lestu fyrst þennan texta: „Lodin sagði einnig að embættismenn hefðu ákveðið að hætta við úrslitaviðureignina í kostnaðarskyni fyrir Afgani og vegna öryggisáhættu samfara öðrum kosningum. Diplómatar sögðust hafa fundið út að afganska stjórnarskráin væri nógu óljós til að sjá að ekki væri þörf á lokakosningunni. Þetta stangast á við fyrri fregnir sem sögðu að ef hætta yrði við viðbótarumferðina væri það brot gegn stjórnarskránni.“
Samkvæmt því sem fram kemur í kaflanum, hver þessara ástæðna var ekki notuð til að útskýra af hverju hætt var við úrslitaviðureignina?
A: Öryggisáhætta
B: Ósamræmi í stjórnarskrá
C: Hár kostnaður
D: Óljós stjórnarskrá
Rétt svar: B
AI2 Reasoning Challenge (ARC) is a benchmark by Allen Institute for AI [6]. The benchmark consists of multiple-choice questions about elementary school-level science that require both general knowledge and logical reasoning to answer correctly. The questions were specifically selected to be challenging for language models when the benchmark was created in 2018, but have mostly become trivial for the most capable language models today in English. We machine-translated the benchmark into Icelandic with the help of Claude 3.5 Sonnet. Here's an example question:
As part of an experiment, an astronaut takes a scale to the Moon and weighs himself. The scale reads 31 pounds. If the astronaut has a mass of about 84 kilograms, which are the approximate weight and mass of the astronaut when standing on the Earth?
A: 31 pounds and 14 kilograms
B: 31 pounds and 84 kilograms
C: 186 pounds and 14 kilograms
D: 186 pounds and 84 kilograms
Correct answer: D
Original:
Sem hluti af tilraun tekur geimfari með sér vog til tunglsins og vigtast. Vogin sýnir 31 pund. Ef geimfarinn er um 84 kíló að massa, hver eru líkleg þyngd og massi geimfarans þegar hann stendur á jörðinni?
A: 31 pund og 14 kíló
B: 31 pund og 84 kíló
C: 186 pund og 14 kíló
D: 186 pund og 84 kíló
Rétt svar: D
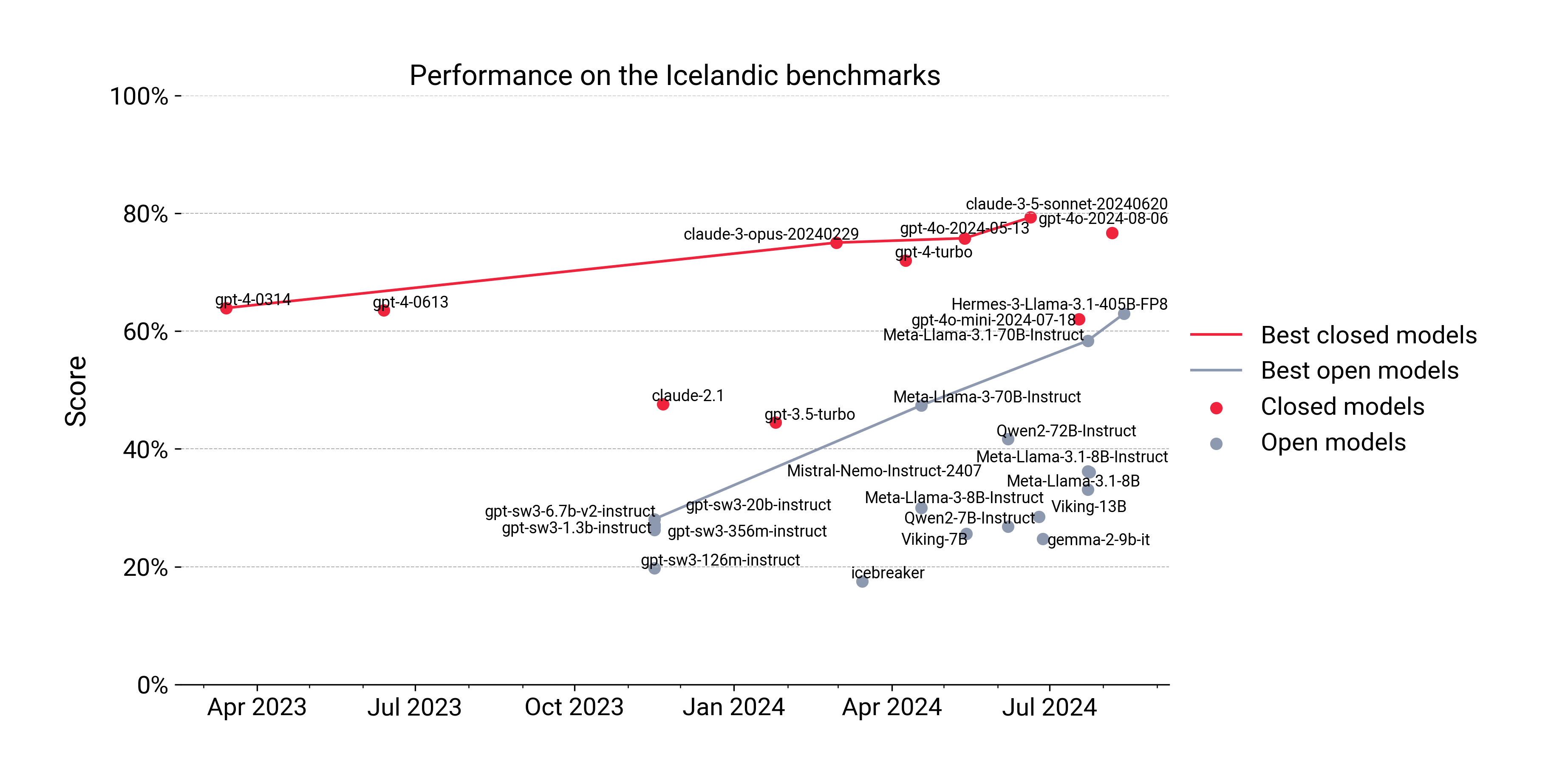
By looking at progress on the leaderboard over time, the superiority of closed models on the Icelandic benchmarks becomes abundantly clear. Even the first version of GPT-4 from March 2023 outperforms the currently most capable open model, Llama 3.1. Still, the open models seem to be making steady progress, and hopefully, we can expect their improvement to continue in the coming years. It's also worth keeping in mind that the open models we publish on the leaderboard are likely considerably smaller than the closed models that OpenAI and Anthropic have in production, so the comparison may not be entirely fair.
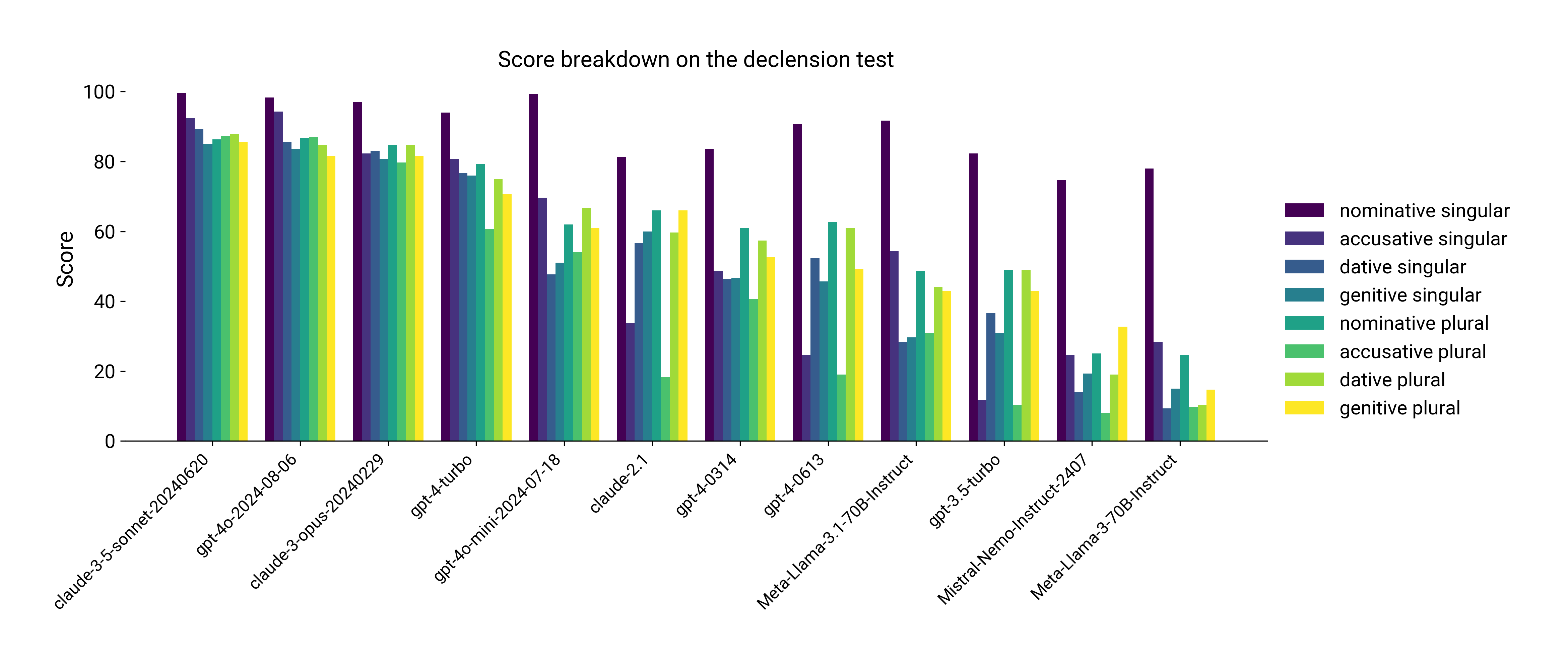
For fun, we can take a closer look at the results from the declension benchmark in the figure below. There we see selected models from the scoreboard where the score has been broken down by case and plurality. The nominative singular doesn't pose much difficulty for the models, as that is the form that is given when the questions are posed. However, proficiency in oblique cases and plural forms deteriorates rapidly as we move down the scoreboard, and the accusative plural seems to be particularly challenging.
The scoreboard we have presented here provides important insight into the capability of language models in Icelandic. However, it's worth keeping in mind that the benchmarks don't cover all aspects of Icelandic proficiency, and therefore the results should be interpreted with care. In particular, the scoreboard is missing a benchmark that systematically evaluates language generation quality. We plan to add more benchmarks and update the scoreboard regularly to give the most accurate picture of the situation. We look forward to following the developments, as this project is important for the future of Icelandic in the world of artificial intelligence.
[1] https://arxiv.org/abs/2009.03300
[2] https://openai.com/index/learning-to-reason-with-llms/
[3] https://arxiv.org/abs/2311.12022
[4] https://winogrande.allenai.org/
[5] https://ai.meta.com/research/publications/the-belebele-benchmark-a-parallel-reading-comprehension-dataset-in-122-language-variants/
[6] https://arxiv.org/abs/1803.05457