We are delighted to present an open prototype of a new thesaurus for the Icelandic language. This new resource, which was compiled with the help of artificial intelligence and open source dictionary data, is available at samheiti.is.
A thesaurus is a useful tool in writing when we want to make our language more nuanced, find a word that evades us, or simply learn new words. A good thesaurus can stimulate curiosity and enjoyment from language and simultaneously remind us how important word choice is in creating rich and meaningful text. What associative connections, for example, come with reading the following words?
ilmur - angan - lykt - þefur - remma - daunn - fnykur
(fragrance - scent - smell - odor - tang - stench - reek)
Words can be relatively neutral, like "smell," or evoke strong impressions, like "stench." Words have an impact, and with a thesaurus, you can search for precisely the right word for any given context.
This new thesaurus is the result of an experiment we at Miðeind undertook to test the capacity of the latest GPT models from OpenAI, and there was considerable uncertainty about the outcome. The project relies on the GPT-4o AI model having sufficient understanding of Icelandic to discern precise nuances in word meaning. We took a data-driven approach, using AI to assess existing word data and classify words that can be considered synonyms. The results of this experimental project exceeded our expectations, and so we present the outcome as a new resource for the Icelandic-speaking community.
Large language models (such as GPT models, Claude, Gemini, and others) have acquired extensive knowledge of the world's languages from their training data and prove to be sensitive to nuances in meaning. This knowledge, in addition to all the Icelandic text data they have been trained on, makes them powerful tools that can be used to evaluate and classify text. Things are moving quickly, but as it stands now, the Icelandic comprehension capability of these LLMs is such that their understanding still exceeds their ability to generate flawless and grammatically correct Icelandic text. The key is to give the model text to process, analyze, modify, or classify in some way, rather than having it generate text from scratch.
Some of the best uses for large language models are when they are tasked with work that would be impossible or extremely time-consuming and tedious for people to do. Usually, it would take many years of tedious work by language experts work to create a thesaurus, but we can harness the knowledge that lies in valuable data created over the years by experts in Icelandic, semantics, and lexicography, and combine it into a new tool for people writing in Icelandic.
The prerequisite for being able to do this work with automated methods is therefore twofold: artificial intelligence technology and data. The data underlying this new thesaurus comes primarily from the Dictionary of Contemporary Icelandic, which is a large electronic dictionary developed by the lexicography department at the Árni Magnússon Institute for Icelandic Studies, containing over 56,000 headwords and forms the foundation of the thesaurus. In addition, we also used data from IceWordNet , the Icelandic portion of the Princeton WordNet, which contains synonyms for about 5,000 common words in Icelandic. Finally, we used a subset of the data available at Icelandic Wordweb, which is a detailed dictionary/database with diverse semantic relations between Icelandic words and phrases. All these data can be accessed openly at the CLARIN repository.
As we know, a single word can have multiple meanings or semantic fields. Sometimes the semantic fields of a word are very distinct, such as gos (‘soda’ or ‘volcanic eruption’), but often it's harder to discern the difference. For example, kaffibolli ('coffee cup') has two defined semantic fields in the Dictionary of Contemporary Icelandic: kaffibolli as the container that one drinks from (kaffibollinn brotnaði, "the coffee cup broke"), and kaffibolli as the cup plus the coffee that is drunk from it (fá sér kaffibolla, "have a cup of coffee"). Some words have numerous meanings, even dozens, especially verbs that can take various prepositions, such as setja ‘put’ (setja fram, setja í, setja upp...). And as no dictionary is exhaustive, there are countless semantic fields that have yet to make it into dictionaries.
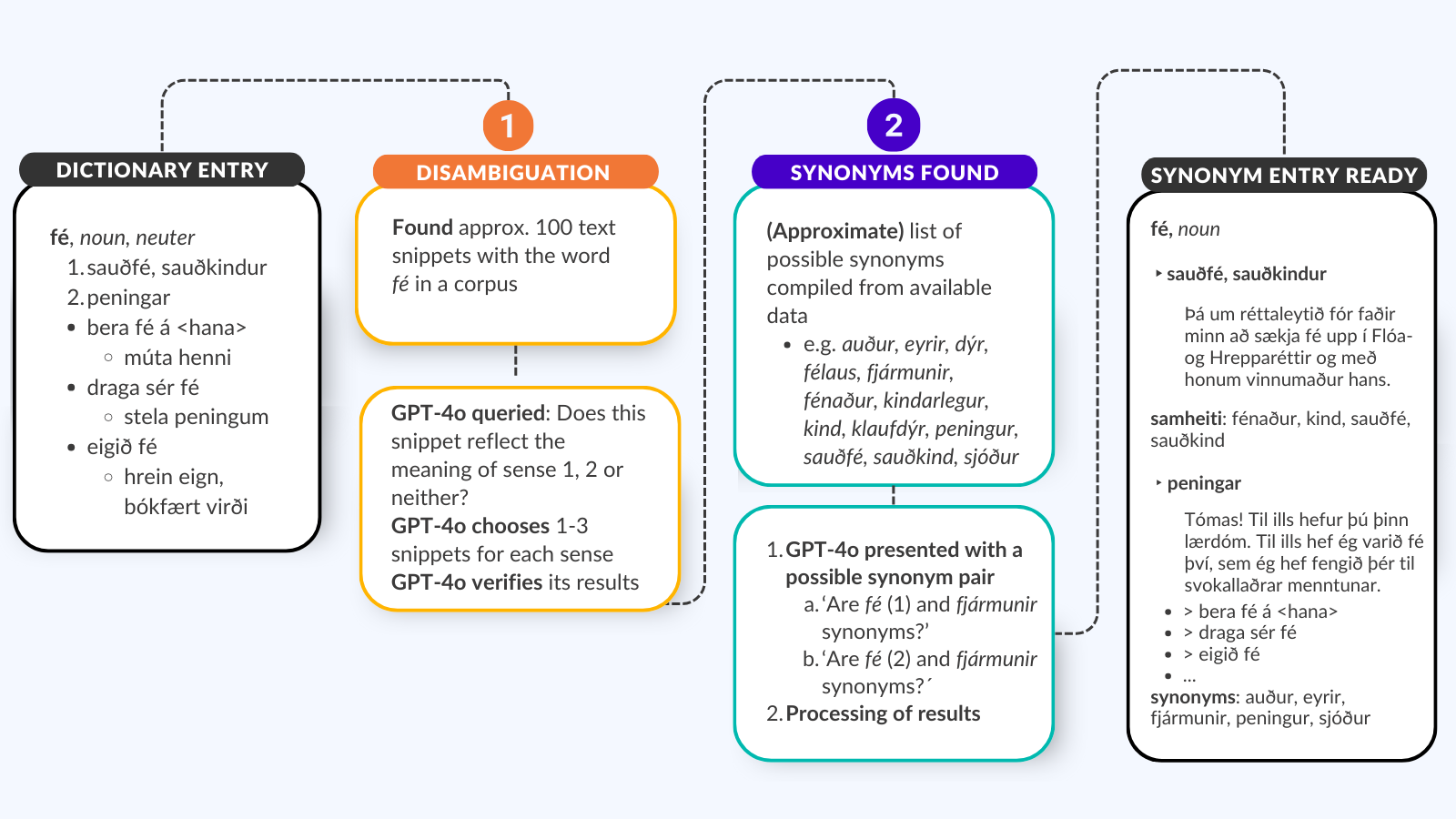
This was a particular challenge in this project as different semantic fields can also have different synonyms. For example, eldgos ('volcanic eruption') is only a synonym for gos in one of its meanings, not the other. For the verb setja ('put'), one can also put down potatoes, put up a play, put forth laws, and so on. Different synonyms apply to each of these domains, depending on usage and meaning. One task in language technology involves such semantic disambiguation, mapping the semantic fields of words based on their context. In this project we applied the GPT-4o model from OpenAI to help us solve this for Icelandic. This was an important preparatory step for the thesaurus functionality.
In order to capture the word in diverse contexts, for each headword (entry) in the Dictionary of Contemporary Icelandic, we searched the Icelandic Gigaword Corpus (a large collection of Icelandic texts) for various text fragments where the word appears in different forms.
When the text examples had been identified, we filtered them find the best examples for each meaning of the headword. Next, GPT-4o was asked to judge whether a particular word was used in a given meaning in the text example. This had to be repeated for each semantic field and many text examples but, eventually, a collection of text examples was created for each semantic field.
For extra reassurance, we then had the AI evaluate its own answers and score the text examples based on how well they fit the meaning. This worked well, and the model seemed to have a good understanding of nuances in meaning within Icelandic texts. The result was a dataset where most semantic fields of each word in the Dictionary of Contemporary Icelandic are accompanied by one to three text examples where the word appears in the correct semantic context. This is a dataset that can be useful in various projects where text meaning needs to be analysed, and to our knowledge, is the first of its kind for Icelandic.
The next step was to create the actual thesaurus functionality, which involved asking GPT-4o to assess whether two words/phrases should be classified as synonyms. For this step, we needed to find candidate words in our data that could potentially be synonyms. In addition to the Dictionary of Contemporary Icelandic, we now turned to the two-word nets described above. From these data sources, we were able to compile a list of potential synonyms for each headword. However, this list was by no means precise and existed only for the headword, not for each semantic field. The next step was then to carefully compose prompts for the model. It is important that such prompts are clear enough for the model to understand what is expected and to minimise inaccuracies in responses.
In the prompts, the model was shown two candidates for possible synonyms along with all available dictionary information and text examples with the correct meaning. This was repeated for every single semantic field of each word. This meant numerous queries to the model, nearly a million in total. We benefited greatly from our collaboration with OpenAI, who have enabled us to experiment with this and other pilot projects, and have shown great interest in ensuring that Icelandic in GPT models is as good as it can be.
To give an example of a prompt, the model was shown the word aur in the meaning of 'money,' along with a text example containing the phrase Fyrir ferðina inn að Rauðará fékk ég 25 aura (‘For the trip to Rauðará I received 25 aur’). The same query asked about the word eyrir (‘unit of money’), along with a text example containing Ég hef haldið saman öllu kaupi mínu og engum eyri eytt í neitt (‘I have saved all my earnings and not spent a single eyrir on anything’). All available information from the Dictionary of Contemporary Icelandic was also shown, and the model was asked various questions about whether this word pair belongs in a thesaurus. But since the word aur has other meanings, such as 'mud,' queries were sent for each and every semantic field of the word, against all semantic fields of all words that were on the candidate list for aur. This tested the model's ability to take in all information about the word and make a correct assessment.
All queries were then sent to the model, and the results were processed. This involved compiling, for each word and each semantic field, all words that the model had assessed as synonyms. This data is now accessible to the public at samheiti.is.
In the image above, you can see an example of the synonym compiling process for the word fé, which has two well-known semantic fields, 'money' and 'sheep'. First, GPT-4o is asked to find text fragments for each semantic field, and once these are obtained, the model uses these text examples and all information about the word fé to determine its synonyms from given candidates. This creates an entry with real text examples and synonyms for each meaning.
Since this was an experimental project, the outcome was uncertain. The result is a thesaurus with more than 30,000 headwords that have one or more synonyms for their semantic fields, and some have many. The words with the most synonyms are the noun rógur ('slander') and the adjective uppstökkur ('touchy'), both with 63 recorded synonyms, followed by ósannindi ('untruths'), ofbeldi ('violence'), vanlíðan ('discomfort'), ólæti ('commotion'), rembingur ('pomposity') and hroki ('arrogance'). It could be a research topic in itself as to why the words with the most synonyms are all so negative!
The results are promising for the use of large language models in larger projects for Icelandic. However, this version is only a prototype, and when using automated methods for a project it is to be expected that errors, inappropriate or obsolete words, or other unexpected issues. This is why we have created a function to enable community feedback. If you see something questionable, something you think is missing or doesn't fit, we ask that you please let us know by clicking the three dots next to the entry in question. This will help us to make the thesaurus better for all users.
The plan is to make this functionality accessible when people write text in Málfríður, to help them find exactly the right word each time. There are numerous other possibilities for utilizing and enriching this data, so it's worth keeping an eye on new features as they appear on Málstaður.
Eiríkur Rögnvaldsson (2013). IceWordNet, Retrieved from CLARIN-IS: http://hdl.handle.net/20.500.12537/207.
Halldóra Jónsdóttir and Þórdís Úlfarsdóttir (2020). A Dictionary of Contemporary Icelandic. Retrieved from CLARIN-IS: http://hdl.handle.net/20.500.12537/94.
Jón Hilmar Jónsson, Hjalti Daníelsson, Þórður Arnar Árnason and Alec Shaw (2021). The Icelandic Wordweb. Retrieved from CLARIN-IS: http://hdl.handle.net/20.500.12537/117.
Starkaður Barkarson et al. (2022). Icelandic Gigaword Corpus (IGC-2022) - unannotated version. Retrieved from CLARIN-IS: http://hdl.handle.net/20.500.12537/253.