Við kynnum hér opna frumgerð af nýrri samheitaorðabók fyrir íslensku, sem var tekin saman með hjálp gervigreindar og opinna orðabókagagna, á vefnum samheiti.is.
Samheitaorðabók er gagnlegt verkfæri á ritvellinum, þegar við viljum gera mál okkar blæbrigðaríkara, finna orð sem er alveg á tungubroddinum en við náum ekki að muna, eða einfaldlega læra ný orð. Góð samheitaorðabók getur verið mjög skemmtileg lesning og minnir okkur um leið á það hvað orðaval skiptir miklu máli. Hvaða hugrenningartengsl fylgja til dæmis við lestur eftirfarandi orða?
ilmur - angan - lykt - þefur - remma - daunn - fnykur
Orð geta verið tiltölulega hlutlaus, eins og „lykt“, eða vakið sterk hughrif, eins og „fnykur“. Orð hafa áhrif, og með samheitaorðabók er hægt að leita að nákvæmlega rétta orðinu fyrir samhengið.
Þessi nýja samheitaorðabók er í raun tilraun sem við hjá Miðeind lögðum í til að reyna á þanþol nýjustu GPT-líkananna frá OpenAI, og talsverð óvissa var um hvað kæmi út. Verkefnið reiðir sig nefnilega á að GPT-4o-gervigreindarlíkanið hafi nægan skilning á íslensku til að greina nákvæm blæbrigði í merkingu orða. Við fórum gagnadrifna leið, og notuðum gervigreindina til að leggja mat á orðagögn sem til eru, og flokka þau orð sem geta talist sem samheiti. Niðurstöðurnar úr þessu tilraunaverkefni voru framar vonum og því viljum við deila afrakstrinum með öðrum.
Það eru ótal leiðir til að nota stór mállíkön (eins og GPT-líkönin, Claude, Gemini og önnur) aðrar en að biðja þau um að semja texta. Hlutirnir gerast hratt en eins og staðan er núna þá er íslenskugeta þeirra bestu enn þannig að íslenskuskilningurinn er meiri en getan til að mynda lýtalausa og málfræðilega rétta íslensku. Þennan málskilning er þó með snjöllum aðferðum hægt að nýta á ýmsa vegu til að leysa fjölbreytt verkefni. Þar skiptir mestu að gefa líkaninu texta til að vinna úr, greina, breyta eða flokka á einhvern hátt, í stað þess að láta það mynda texta frá grunni.
Stór mállíkön hafa öðlast mikla þekkingu á tungumálum heimsins úr þjálfunargögnum sínum og reynast vera næm fyrir blæbrigðum í merkingu. Þessi þekking, til viðbótar við öll þau íslensku textagögn sem þau hafa verið þjálfuð á, gerir þau að öflugu tóli sem má nota til að leggja mat á og flokka texta. Einhver bestu notin sem finna má fyrir stór mállíkön eru þegar þau eru látin vinna verk sem ógerningur eða afar tímafrekt og leiðigjarnt væri fyrir fólk að vinna. Yfirleitt tæki það mörg ár af sérfræðivinnu að búa til samheitaorðabók, en virkja má þá þekkingu sem liggur í verðmætum gögnum sem hafa verið búin til í áranna rás af sérfræðingum í íslensku, merkingarfræði og orðabókarfræðum, og sameina hana í nýju verkfæri fyrir fólk sem skrifar á íslensku.
Forsenda þess að hægt sé að vinna þetta verk með sjálfvirkum aðferðum er því annars vegar gervigreindartæknin og hins vegar gögnin. Gögnin sem liggja undir þessari nýju samheitavirkni eru fyrst og fremst Íslensk nútímamálsorðabók, sem er stór rafræn orðabók unnin hjá orðfræðisviði Stofnunar Árna Magnússonar, en hún inniheldur yfir 56 þúsund uppflettiorð og myndar grunninn að samheitaorðabókinni. Við nýttum líka IceWordNet-gögnin, íslenskan hluta Princeton-orðanetsins, en þar koma fyrir samheiti fyrir um 5000 algeng orð í íslensku. Að lokum notuðum við hluta Íslensks orðanets, sem er ítarlegt orðasafn með fjölbreyttum merkingarvenslum íslenskra orða og orðasambanda. Öll þessi gögn má nálgast í opnum aðgangi á varðveislusvæði CLARIN.
Eins og við vitum getur eitt orð haft margar merkingar eða merkingarsvið. Stundum eru merkingarsvið orðs mjög ólík, svo sem „gos“ (drykkur eða eldgos), en oft er erfiðara að átta sig á muninum. Kaffibolli hefur til dæmis tvö skilgreind merkingarsvið í Íslenskri nútímamálsorðabók: kaffibolli sem ílátið sem er drukkið úr („kaffibollinn brotnaði“), og svo kaffibolli sem bollinn + kaffið sem er drukkið úr honum („fá sér kaffibolla“). Sum orð hafa svo mjög margar merkingar, jafnvel marga tugi, sér í lagi sagnorð sem geta tekið með sér alls kyns forsetningar. Síðan eru ótalin þau merkingarsvið sem enn hafa ekki ratað í orðabækur, en þau eru fjölmörg, því engin orðabók er tæmandi.
Ólík merkingarsvið hafa ólík samheiti. Til dæmis er „eldgos“ bara samheiti orðsins „gos“ í annarri merkingunni en ekki hinni. Það er líka hægt að setja niður kartöflur, setja upp leikrit, setja lög, setja sér markmið, setja fram kenningu, setja eitthvað fyrir sig og svo framvegis. Mismunandi samheiti eiga við um hvert þessara sviða, allt eftir notkun og merkingu. Eitt verkefni í máltækni snýr að þess konar merkingareinræðingu, að kortleggja merkingarsvið orða út frá samhengi þeirra, og við fengum GPT-4o-líkanið frá OpenAI til að hjálpa okkur við að leysa það fyrir íslensku. Þetta var mikilvægt undirbúningsskref fyrir samheitavirknina.
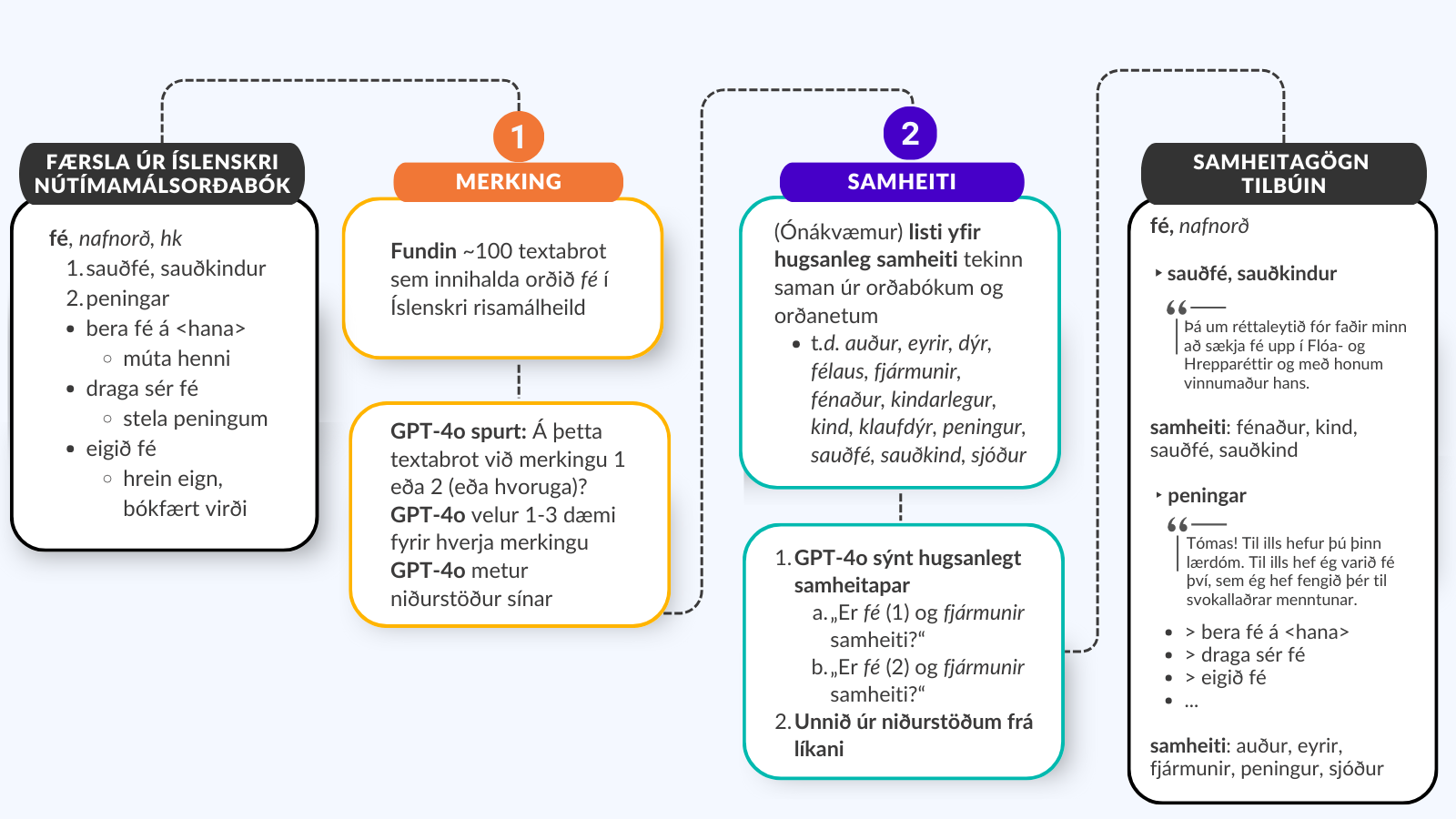
Fyrir hvert uppflettiorð (flettu) í Íslenskri nútímamálsorðabók leituðum við í Risamálheildinni (stórt safn íslenskra texta) að alls kyns textabrotum þar sem orðið kemur fyrir í ýmsum myndum. Þarna var kastað stóru neti og reynt að fanga orðið í fjölbreyttu samhengi.
Þegar textadæmin voru fundin var komið að því að sía textana og finna bestu dæmin fyrir hverja merkingu uppflettiorðsins. Þá kom að því að spyrja GPT-4o, sem dæmdi um hvort tiltekið orð væri notað í gefinni merkingu í textadæminu. Þetta þurfti að endurtaka fyrir hvert merkingarsvið og mörg textadæmi, en á endanum varð til safn textadæma fyrir hvert merkingarsvið.
Til öryggis létum við gervigreindina svo meta sín eigin svör eftir á, og gefa textadæmunum einkunn eftir því hversu vel þau áttu við merkinguna. Þetta gaf góða raun, og líkanið virtist hafa góðan skilning á blæbrigðum í merkingu í íslenskum textum. Útkoman var gagnasafn þar sem flestum merkingarsviðum hvers orð í Íslenskri nútímamálsorðabók fylgja 1-3 textadæmi þar sem orðið kemur fyrir í réttu merkingarlegu samhengi. Þetta eru gögn sem geta nýst í ýmsum verkefnum þar sem greina þarf merkingu texta, og eru fyrstu gögn af sínu tagi fyrir íslensku svo vitað sé.
Þá var komið að sjálfri samheitavirkninni, sem snerist um að biðja GPT-4o um að leggja mat á það hvort tvö orð/orðasambönd ættu að flokkast sem samheiti. Þá þurftum við að finna í gögnunum kandídata orða sem gætu mögulega verið samheiti. Til viðbótar við Íslenska nútímamálsorðabók kom nú til kasta orðanetanna tveggja sem lýst var hér að framan. Upp úr þessum gagnalindum var unnt að vinna lista yfir hugsanleg samheiti fyrir hvert uppflettiorð. Þessi listi var þó engan veginn nákvæmur, og var bara til fyrir uppflettiorðið, ekki hvert merkingarsvið. Næsta skref var þá að semja af kostgæfni fyrirmæli (prompt) fyrir líkanið. Það er mikilvægt að fyrirmæli sem þessi séu nógu skýr til að líkanið skilji til hvers er ætlast og til að lágmarka ónákvæmni í svörum.
Í fyrirmælunum voru líkaninu sýndir tveir kandídatar um möguleg samheiti ásamt öllum tiltækum orðabókarupplýsingum og textadæmum í réttri merkingu. Þetta var endurtekið fyrir hvert einasta merkingarsvið hvers orðs. Þetta þýðir að fyrirspurnirnar til líkansins urðu mjög margar, tæp milljón talsins. Við nutum við þessa vinnu góðs af samstarfi við fyrirtækið OpenAI, sem hefur gert okkur kleift að prófa okkur áfram með þetta og önnur tilraunaverkefni og hefur sýnt mikinn áhuga á því að íslenskan í GPT-líkönum verði eins og best verður á kosið.
Sem dæmi um fyrirmæli var líkaninu sýnt orðið „aur“ í merkingunni „peningur“, og síðan textadæmi þar sem fyrir kemur brotið „Fyrir ferðina inn að Rauðará fékk ég 25 aura“. Í sömu fyrirspurn var spurt um orðið „eyrir“, ásamt textadæmi sem innihélt „Ég hef haldið saman öllu kaupi mínu og engum eyri eytt í neitt“. Einnig voru birtar allar tiltækar upplýsingar úr Íslenskri nútímamálsorðabók, og líkanið beðið að svara ýmsum spurningum um hvort þetta orðapar eigi heima í samheitaorðabók. En þar sem orðið „aur“ hefur aðrar merkingar, til dæmis „eðja“, voru sendar fyrirspurnir fyrir hvert einasta merkingarsvið orðsins, við öll merkingarsvið allra orða sem voru á kandídatalistanum fyrir „aur“. Hér reyndi á að líkanið tæki inn allar upplýsingar um orðið og gæti lagt rétt mat á þær.
Allar þessar fyrirspurnir voru svo sendar til líkansins, og svo var unnið úr niðurstöðunum. Það fólst í því að taka saman, fyrir hvert orð og hvert merkingarsvið, öll orð sem líkanið hafði metið sem samheiti. Þessi gögn voru síðan gerð aðgengileg almenningi á samheiti.is.
Á myndinni hér fyrir ofan má sjá dæmi um ferlið fyrir orðið „fé“, sem hefur tvö vel þekkt merkingarsvið. Fyrst er GPT-4o beðið um að finna textabrot fyrir hvort merkingarsvið, og þegar þau eru komin notar líkanið þessi textadæmi og allar upplýsingar um orðið „fé“ til að ákvarða samheiti þess út frá gefnum kandídötum. Þá verður til færsla með raunverulegum textadæmum og samheitum fyrir hvora merkingu um sig.
Þar sem um tilraunaverkefni var að ræða var alls óvíst hvernig til tækist. Út kom samheitaorðabók með meira en 30.000 uppflettiorðum sem hafa eitt eða fleiri samheiti fyrir merkingarsvið sín, og sum hafa fjöldamörg. Orðin sem flest samheitin hafa eru nafnorðið „rógur“ og lýsingarorðið „uppstökkur“, bæði með 63 skráð samheiti, og þar á eftir koma „ósannindi“, „ofbeldi“, „vanlíðan“, „ólæti“, „rembingur“ og „hroki“. Það er svo annað rannsóknarefni hvers vegna þessi orð eru öll svona neikvæð!
Niðurstöðurnar lofa góðu um notkun stórra mállíkana í stærri verkefnum fyrir íslensku. Þessi útgáfa er þó aðeins frumgerð, og í verkefni sem unnið er með sjálfvirkum aðferðum er alltaf viðbúið að finnist villur, óviðeigandi eða úrelt orð eða annað óvænt. Ef þú sérð eitthvað athugavert, eitthvað sem þér finnst vanta upp á eða ekki eiga við viljum við endilega að þú látir vita af því með því að smella á þrípunktana við hlið viðkomandi færslu. Þá hjálpar þú okkur að gera samheitavirknina betri fyrir alla notendur.
Á dagskrá er svo að gera þessa virkni aðgengilega þegar notendur skrifa texta í Málfríði, til að hjálpa þeim að finna nákvæmlega rétta orðið hverju sinni. Fjölmargir aðrir möguleikar eru svo til að nýta og auðga þessi gögn, svo það er um að gera að fylgjast með nýjungum eftir því sem þær detta inn á Málstað.
Eiríkur Rögnvaldsson (2013). IceWordNet, Sótt af CLARIN-IS: http://hdl.handle.net/20.500.12537/207.
Halldóra Jónsdóttir og Þórdís Úlfarsdóttir (2023). Íslensk nútímamálsorðabók. Sótt af CLARIN-IS: http://hdl.handle.net/20.500.12537/94.
Jón Hilmar Jónsson, Hjalti Daníelsson, Þórður Arnar Árnason og Alec Shaw (2021). Íslenskt orðanet. Sótt af CLARIN-IS: http://hdl.handle.net/20.500.12537/117.
Starkaður Barkarson o.fl. (2022). Íslensk risamálheild (IGC-2022) - ómörkuð útgáfa. Sótt af CLARIN-IS: http://hdl.handle.net/20.500.12537/253.